
The services become more and more complex, with a mix of networking (virtual networking) functions at the edge, the core, and the data center, and the combinations of networking, compute, and storage in the cloud with containers. With this increased complexity today and, at the same time, an increased frequency of changes (ex: scaling up), we know that we need to get the humans out of the loop, to focus on automation. We concluded in the past that data model-driven management will simplify the automation and that the telemetry must be data model-driven.
Now, does the network behave as expected? Are the new services operational? Are the Service Level Agreements (SLA) respected? Well, we could be checking that the network devices, the virtual machines or containers are reachable and we could check that the services or the Virtualized Network Functions (VNFs) are correctly configured. However, validating the configuration and reachability of individual components does not imply that the services are running optimally or meet the SLAs.
The cost of service failures goes significantly up these days. Imagine the monetary implications of a one-hour downtime for Facebook service, whose business model depends solely on the advertisements. Imagine the monetary implications of a one-hour downtime for the Amazon Web Services, whose business model depends on the web service utilization. At a reduced scale, but nonetheless equally important for its owner, what about the down time of the local e-commerce website?
This is where the notion of intent-based networking (IBN) comes to play, with networks constantly learning and adapting. Historically, we have been managing in a prescriptive mode by focusing on detailing the necessary network configuration steps. Contrary to the prescriptive approach, the intent-based approach focuses on the higher-level business policies, on what is expected from the network. In other terms, the prescriptive approach focuses on the how, while the intent-based approach focuses on the what. For example, the prescriptive way to configure a L3VPN service is a series of following tasks, expressing the how. For example, we must configure a VRF called “customer1” on the provider edge router1 under the interface “eth0”, a default gateway pointing to router1 on the customer edge router, the MPLS-VPN connectivity between the provider edge router1 and router2, etc. Alternatively, the intent-based way would focus on what is the required from the network, i.e. a VPN service between the London and Paris sites for our customer C.
Where the intent-based networking creates the most value is with the constant learning, adapting, and optimizing, based on the feedback loop mechanism:
- Decomposition of the business intent (the what) to network configuration (the how). This is where the magic happens. For a single task such as “a VPN service between the site of London and Paris for my customer C”, we need to understand: the corresponding devices in Paris and London, the mapping of the operator topology, the current configuration of the customer devices, the operator core network configuration, the type of topology such as hub and spoke or fully meshed, the required QoS, the type of IP traffic (IPv4 and/or IPv6), the IGP configuration between the customer and the operator, etc. As a reference, examine all the possible parameters for a L3VPN service in the specifications of the YANG Data Model for L3VPN Service Delivery, RFC8299.
- The automation: this is the easy part, once the what is identified. Based on the data-model driven management and a good set of YANG models, a controller or orchestrator translates the YANG service model into a series of network device configurations. Thanks to NETCONF and three-phase commit, we are now sure that all devices are correctly configured.
- The monitoring with data-model driven telemetry provides a real-time view of the network state. Any fault, configuration change, or even behavior change, are directly reported to the controller and orchestrator.
- The data analytic would correlate and analyze the impact of the new network state for service assurance purposes, isolating the root cause issue. Sometimes, even before the degradation happens.
- From there, the next network optimization is deduced, almost in real-time, before going back to step 1 to apply the new optimizations.
This constant feedback loop, described in four phases, is the foundation for networks that constantly learn and adapt. It allows moving away from a reactive network management where a network fault (or worse a customer call) triggers the troubleshooting to constant monitoring focused on the SLAs. The combination of predictive analytics and the artificial intelligence, combined with the continuous learning and adapting, is the main enabler here. From here, the next logical step is not too futuristic: self-healing networks.
All this above is the theory about intent-based networking. We know that Intent-based networking is the end goal and that a compulsory step is to close the loop with telemetry, for service assurance. At this point in time, the big question is: how do we evolve existing networks towards that vision of intent-based networking, self-healing networks, self-driving networks, self-<whatever> networks? Taking into account, obviously, that the vast majority of networks are brown field environments, as opposed to green field ones.
To answer the question, let me take an analogy: the Maslow’s hierarchy of needs.
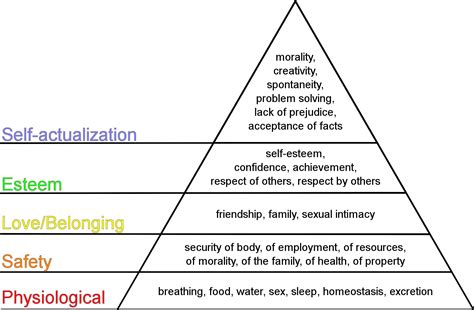
Maslow’s hierarchy is most often displayed as a pyramid. The lowest levels of the pyramid are made up of the most basic needs, while the most complex needs are at the top of the pyramid.
Needs at the bottom of the pyramid are basic physical requirements including the need for food, water, sleep, and warmth. Once these lower-level needs have been met, people can move on to the next level of needs, which are for safety and security.
Now, let’s go back to networking and let me present the Maslow’s Pyramid of Needs for Intent-based Networking (picture from my “Model-driven Telemetry for Closed Loop Automation” Ciscolive session). Exactly like the Maslow’s one, this pyramid consists of distinct levels, with the lower needs/levels required to be met before going up the ladder.
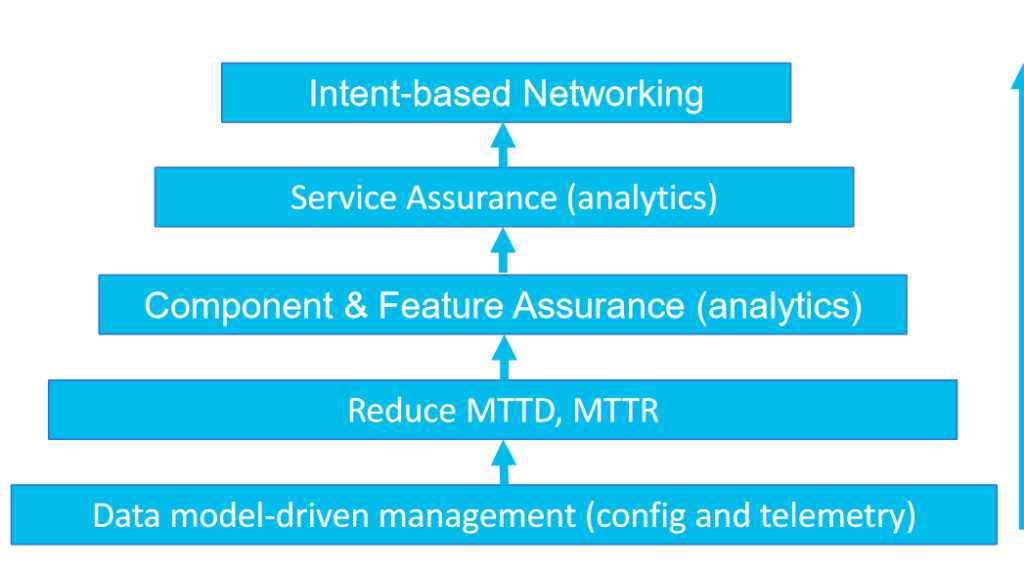
Data model-driven management (both configuration and operational data with telemetry) composes the hierarchy foundational level. I blogged about that numerous times. I hope the message went through 🙂
The next level is the data analysis to reduce the Mean Time To Detect (MTTD) and Mean Time To Repair (MTTR). This task is complex already: without analytics, telemetry is just a haystack of data. Indeed, telemetry can stream a lot of data: a typical IOS-XR ASR9000 router has more than 250,000 YANG leafs in its YANG modules … to be multiplied by the instances number. While telemetry stream data, we’re after information, in order to take an action.
In my opinion, the next level in the hierarchy is the component/feature assurance. What if we could report as a single metric for the router health, the interface health, the IGP health, <you name it> health. Decomposing the total network health into component/feature health provides an important advantage while troubleshooting: we can discard the healthy components to focus on the unhealthy/degraded components. It other words, at troubleshooting time, when time matters, it’s equally important to know where the problem IS NOT than knowing where it might be.
At this point, we’re still missing a key information, the notion of service context. Knowing that a interface/a path is badly behaving is good, but knowing on top of that the affected service instances (and hence which customers) is way better. Let’s not forget that the end goal of networks is to provide reliable services. Logically, the next level up in the pyramid is the service assurance, which requires an assurance graph.
And, finally, the top level, the Maslow’s self-actualization, is the networking nirvana: the intent-based networking, if even possible at all for brown field environments. What is for sure, without going step by step, up in the Maslow’s pyramid of intent-based networking, it will be very difficult.
Towards that vision, here are some interesting references, for your leisure time:
– Service Assurance for Intent-based Networking Architecture
– YANG Modules for Service Assurance
– Per-Node Capabilities for Optimum Operational Data Collection