
It’s obvious that networks become more and more complex these days … for a “network” definition that encompasses: the network itself, the cloud, the application and the end user environment, you-name-it … basically everything that influences the end user Quality of Experience (QoE). Indeed, have you noticed how easy it is to ALWAYS blame the network, regardless of the type of issues?
As a consequence of this complexity, the costs of managing those networks increase. The time to fix a network issue (and hence the cost) is characterised by two metrics:
- The Mean Time To Detect (MTTD), also known as Mean Time to Identify (MTTI)
- The Mean Time to Repair (MTTR)
Most network operators still struggle to quickly and efficiently identify the issue that impacts the service (MTTD), the logical first step before actually fixing the network (MTTR). Expressing this differently: the MTTD associated cost is way higher than the MTTR one. While the industry as a whole still focuses on network visibility to reduce the MTTD, let’s not forget the end goal: solving the autonomous network vision. hat means the ability to automatically repair networks using closed loop actions… and eventually removing the human from the loop.
After the very step of configuration automation (which in my mind is on the right track, even if not yet perfect yet), the next logical phase is the assurance automation. This assurance automation uses the data & control & management planes monitoring (plus some know-how) to monitor devices, networks, services, and more importantly the service intents. This is referred to as Intent-Based Network (IBN). See “The Maslow’s Pyramid of Needs of Intent-based Networking” blog, in which the concepts are explained.
To help on that matter, I am very happy to share those two brand new RFCs:
- RFC 9417, Service Assurance for Intent-Based Networking Architecture

- RFC 9418, A YANG Data Model for Service Assurance

The first RFC specifies an architecture that helps answering two important questions:
- When a service instances degrades, what is/are the fault(s), and what is/are the symptom(s)?
- Which service instance(s) is/are impacted by the symptom(s)? In other terms
That is: instead of having a set of alerts whose impact is hard to understand, each symptom found by the Service Assruance For Intent-based Architecture (SAIN in short)comes with a list of impacted services. Consequently, humans or software can prioritise their resolution actions towards the most impacting symptoms.
The second RFC (9418) specifies the required YANG modules behind the assurance graph specified in the architecture. As I shared in a previous MPLS SD & AI Forum in Paris, here is a Proof-of-Concept example of such an assurance graph.
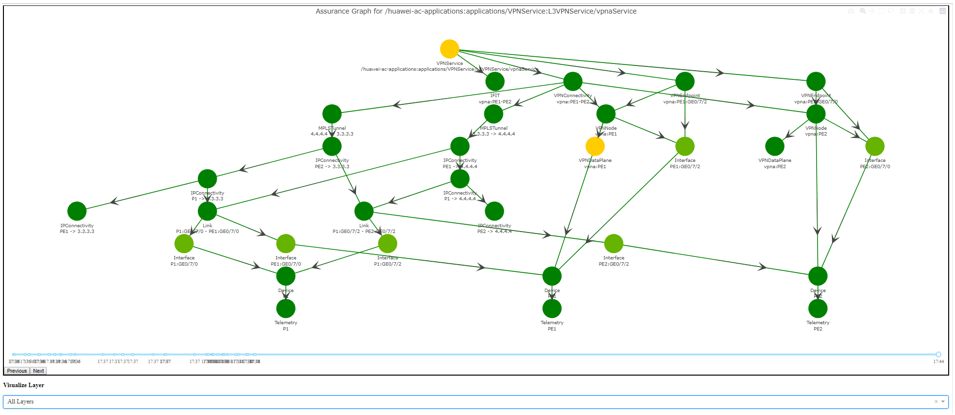
So today, thanks to the IETF, and the many operators co-authors, we standardised a key building towards the realisation of this autonomous networks vision.